�����й���ӭ��~��
![]() ��Ϊ��ҳ
��Ϊ��ҳ
�����й���ӭ��~��
![]() ��Ϊ��ҳ
��Ϊ��ҳ

2024������ǿ�Ĵ��ꡣ
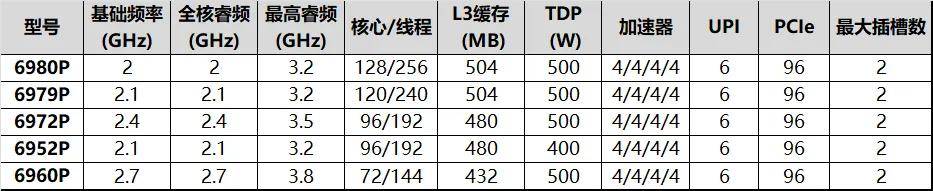
����6����ʽ��������ǿ 6700Eϵ�п�����ȫ�µġ���Ϊ���������ʽ����ǿ 6��Ч�ˡ�144�˵Ĺ��Ҳ��ζ��Ӣ�ض���������굱���״��ں�����������ʵ�������ȡ����ң����������ǿ6����ǿ��̬���Ͼ���Ҷ�֪�����и�6900Pϵ���
9��26�գ���ǿ6�������ǿ��̬��������ʽ��������Ҫ���dz�����ʹ��Խ����������Լ���������������ͬ����CPU����ǿ 6900P�����й��Ҳս��ʮ�㡣

Ӣ�ض�����Birch Stream����һ��������ƽ̨�����õ���ǿ6�������Ƿ����η����ġ�6�·������Ǵ���Sierra Forest����Ч�˴�����6700Eϵ�У�E����Efficiency Core����Ч�˵ı�ǣ���Ŀǰ�������Ǵ���Granite Rapids�����ܺ�6900Pϵ�С���������������½������6900E��6700P���Լ�6500/6300�ȡ�δ����Intel 18A���칤�յĴ���������Clearwater Forest��Ҳ���������Birch Streamƽ̨��
��ǿ6900P��Ӣ�ض�רΪ�����ܼ�����������ƵĴ�������Ҳ��Granite Rapids�ġ���ȫ�塱�����ġ�P����ζ����õ���Performance Core�������ܺˣ���ģ������ǿ��6900�������ͺ���˵��������������������ṩ��72��128�˵Ķ��ֹ��TDP��400W��500W���֣���ϳ��ѹ���5���ͺţ��ԵñȽϼ�ࡣ��Ȼ�����չ������Ƴ��̵ȴ�ͻ����������ɶ����ͺŵġ������ں��������ԣ�6900Pϵ�����ǰ������Rapids����Ʒ�߶����56/60��Sapphire Rapids����64�ˣ�Emerald Rapids��ֱ�ӷ�������˾�ĵ������ȷdz�������Ҳ�ѹ�Ӣ�ض�Ҫ��������ʽ�ˣ��ɱ����ﶼ��һ����˼�������������̥���ǣ�
��Ϊֵ��һ����ǣ���ǿ6900PҲ��ҵ�������ܺ�������ʽ���ư١��IJ�Ʒ������ͬ����Ʒ��������x86�ܹ�����Arm�ܹ���ֻ�ﵽ��96�˵�ˮƽ�����ǵ����ܺ�����ҪƽӢ�ض�������õȵ��¸����ȡ�
�����ں˹�ģ���ӣ���ǿ6900P��L3����ﵽ��504MB��Ϊ����ϱ����ĺ�����������������������ǿ6900ϵ�еĴ���Ҳ��Ϊ��ǿ���ڴ�������治��֧��12ͨ��DDR5 6400���������������ڴ�MR DIMM���������ʴ��������8800MT/s�������ڴ�������Դﵽ�������ǿ����չ��������2.3�������⣬��ǿ6��֧��CXL 2.0�������ǰ���Type 3�豸��Ҳ����CXL�ڴ棩�����Խ�һ����չ�ڴ������ʹ�����
��ǿ6900P��UPI2.0��·Ҳ�кܴ�Ľ�������������24GT/s������������6����ʹ��˫·����Ч�ʽ�һ������������ں��������ڴ�����ȷ����ȫ����������ǿ6900P���Ա�����������+�ߴ���ƽ̨����ǿ��ͷ�������ǿ�ѧ���㣬����AI��Ⱥ��������¶�IJ��ԣ���ǿ6900Pƽ̨�����ݿ⡢��ѧ����ȹؼ�Ӧ�ø��صı�������һ����Ʒ��2.31��-2.5����AIӦ����������1.83��-2.4�����ȡ�


��ǿ6����չ����Ҳ�в�С������������6900ϵ�е��������������ܺ˻�����Ч�˾����ṩ96ͨ��PCIe 5.0��˫·�����ṩ192ͨ��PCIe 5.0��δ�����е�6700ϵ�е�·�ͺſ����ṩ136ͨ��PCIe 5.0��˫/��·�ͺŵ����Ҳ�����ṩ88ͨ������϶��ԣ����ġ������ǿ����չ��������PCIe 5.0ͨ������Ϊ80��CXL֧���������棬��ǿ6 6900��6700ϵ�ж�֧��64ͨ��CXL 2.0��
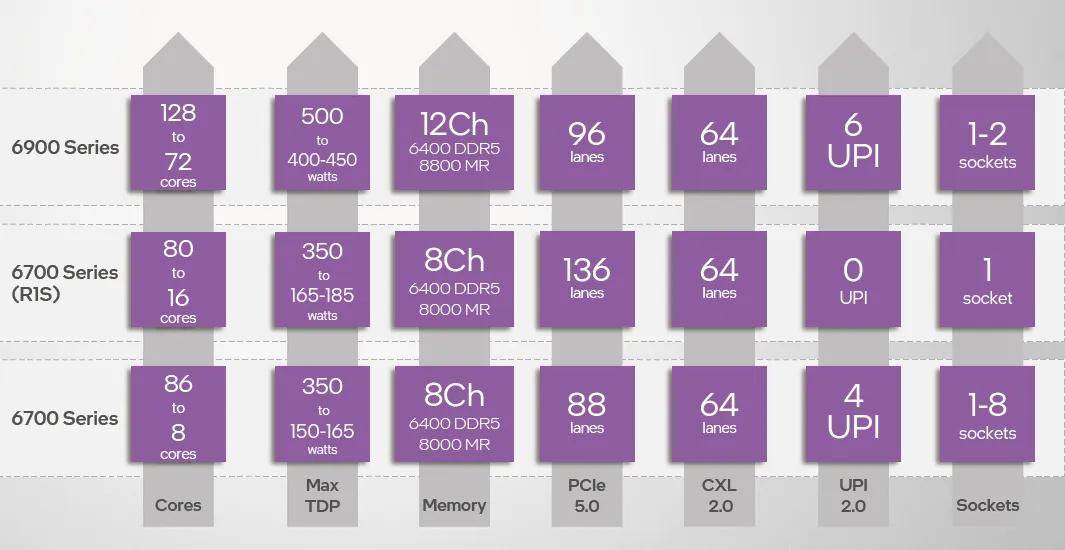
������ںˡ�������ڴ�ͨ���������PCIeͨ����Ҫ�����ģ�IJ����ӿ�֧�֡� ��ǿ6���������ֽӿڣ�LGA 4710��LGA 7529����ǿ6900ϵ��ʹ������ϴ��LGA 7529�������ṩ��ǿ����ڴ��������չ��������δ�������ܡ����ܶȷ������Ļ�������ǿ6700�Լ�δ����6500/6300ϵ��ʹ��LGA 4710���ߴ�����ġ������ǿ��LGA 4677��£��ڴ桢PCIe��ͨ������ͬ������������������������ڲ�����ϰ�ߵ������ԡ�
���Ĺ�ģ��������ȵ�������ǿ��Ʒ�����ڻ��EUV��̻��ļӳ֡���2023�귢���Ŀ��Ultra�Ѿ�����ʹ��������EUV��Intel 4���칤�ա���2024�귢������ǿ6��ʹ���˽�һ��������Intel 3���칤�ա�
2021��7�£�Ӣ�ض�CEO���ء����������ˡ���������Ƴ̽ڵ㡱��5N4Y���Ĺ���·��ͼ��Intel 3������ʱ��ڵ�λ��2023��ף�����������ϼƻ����ӻ���Intel 4���칤�յĿ��Ultra���г����ֿ���EUV�ļӳ�ȷʵ����������Ӣ�ض��������ľ���������ǿ6�����õ�Intel 3���칤�����Intel 4���Թ滮����Ľ����㡢ӵ�и���ϸ�ְ汾��

Intel 3�ڸ���IJ�����Ӧ��EUV��̣������ṩ���ܼ�����ƿ⡢���ߵľ��������������Intel 3�������ֱ��壬����3-T��3-E��3-PT��Intel 3��3-T�ǻ������գ���Ҫ����CPU��3-E�ǹ�����չ�����߶�֧��TSV��Intel 3�������ֱ�����Intel 4��ȿ�������18%�����ܹ��ıȡ���3-PT��һ�����ӻ�ϼ��ϵ�֧�������������˸��ߵ����ܲ�������ʹ�á�Intel 3�������ֽڵ���嶼֧��240 nm�����ܺ�210 nm���ܶȿ⣬��Intel 4ֻ֧��240 nm�����ܿ⡣
��������ȡ��Intel 3��Ը�������������Ż�������֧�ֵ͵�ѹ(<0.65V)��ѹ(>1.3V)���У����ڸ���ѹ�µ�Ƶ�ʾ�����Intel 4��

��ǿ6900P���õ����ܺ��ܹ�����Redwood Cove��Redwood CoveҲ�ǽ�����Ӣ�ض�����Ҫ���ܹ���������������������Ʒ�ߴ����������֣����������Ʒ��ͬ���������µ��������п��Ultra��
�����ȿ��ٻع�һ��Redwood Cove����һ��Golden Cove/ Raptor Cove��Golden Cove��ʵҲ�Ƿdz���Ҫ�ĵ���������������˴�С��ʱ������12��������������ڷ������Ͼ��ǵ��Ĵ���ǿ����չ��������Golden Cove�����ǰ�����ܹ������������ǰ�ˣ�
ָ��TLB��������128�����ӵ�256����
ָ����ȡ������ÿ����16�ֽڷ�����32�ֽڣ�
��������4·��չ��6·��
���������2304�����ӵ�4096����
����L1 BTB��L2 BTB��Ҳ����������
Golden Cove�ĺ�˵�ȻҲ��������Ʃ��������������֧Ŀ�껺����Ҳ�д��30%���ҵ�������ֻ�����ǰ�˷��Ȳ���ô��
Raptor Cove���ܹ���Golden Cove���첻������ʵ�ʲ�Ʒ����Ҫ�ǻ���������������Raptor Coved�ĵ�13�����Raptor Lake����ÿ����L2�����12����Alder Lake����1.25MB������2MB���������ǿ����չ��������Emerald Rapids���͵��Ĵ���Sapphire Rapids��ÿ�����ĵ�L2���涼��2MB����ǰ��ÿ�������ĩ�����棨Last Level Cache��Ҳ�ɼ����׳�ΪL3���棩�Ӻ��ߵ�1.875MB������5MB��
Redwood Cove���Golden Cove/ Raptor Cove������Ҫ�仯�ǣ�
ָ����32KB���ӵ���16·��64KB��
�������д�144����Ŀ���ӵ�192����Ŀ��
ָ��ִ���ӳٽ��ͣ�
�����ܵ�Ԥȡ�Ľ���BPU��
L2����Ĵ�������������
AMX����FP16֧�֡�
��Ȼ��Redwood Cove����һ���ش�����ƾ��ǡ����á���Ҳ����ǰ���ᵽ��EUV���칤�ա�����ʹ�и����Ե����칤�ռӳ֣���ǿ6���ܺ�Ҳû��������ÿ���ں˵Ĺ�ģ������ǿ6���ܺ˵��ں˶��ԣ�ÿ������ڵ���һ��P�ˣ�ÿ��P������˽�е�2MB L2���棬�Լ�������4MB ĩ�����档��Ȼƽ����ÿ���˵Ļ���������������һ����ǿ��Emerald Rapids���࣬��ʤ���ܺ�����������ǿ6���ܺ�ÿ���������ɹ�����ĩ���������������ɴﵽ504MB��Զ���������320MB�͵��Ĵ���112.5MB��
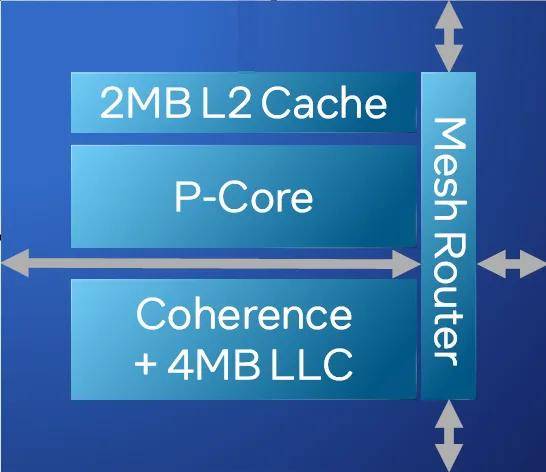
�ڴ�Ҳ˳����һ����ǿ6��Ч�˵��ܹ�Crestmont������ܹ�ͬ���������˿��Ultra����Ч�˵��С�Crestmont��2��4���ں�Ϊһ�鹲��L2���档����ǿ6��Ч�˵��У�ÿ2��4���ں���4MB��L2���棨�ڿ��Ultra����Ϊ2MB������һ��ģ�飬�⼸���ں˹���Ƶ�ʺ͵�ѹ�����ģ���Ӧ������ӵ�п�����������ȫ���ں˹�����3MB��ĩ�����档���仰˵����Ȼ��ǿ6��Ч�˵ĺ������࣬��ʵ���������ģ����ǿ6���ܺ�С��

��Ч�˵�ָ��������ܺ˶���64KB�������ݻ���ֱ���32KB��48KB��ǰ�˵�ָ�����������Ҳ�в��죬�ֱ�Ϊ6��8����ָ������ִ���������ϴ���Ч����256�������ܺ���512������Ч�˲�֧�����ܺ���֧�ֵ�AVX-512��AMX����Ҳ�������Լ�Сʸ�����㵥Ԫ�ľ����ռ�ã���������ÿ���ڵĵ����ȸ���������������������IJ��졣����Ч��Ҳ�Ľ���AVX2��������VNNI��INT8��BF16/FP16����ת���������ڴ���AIӦ�õ�ʱ�����Ҳ���������ơ����⣬��256λ���ܺ�1024/2048��ԿҲ�������Ч�˵�֧�֣�ȷ����ǿ6ƽ̨�İ�ȫˮƽ����һ�¡�

�����ģ��ǰ�˿����Լ�ʸ����Ԫ�IJ��죬ʹ����ǿ6���ܺ˺���Ч���в�ͬ�Ķ�λ�����ȷ�������ǿ6��Ч�˸��ʺ����������ǿ����Խ��ᣬ���ڸߺ���������ģ��չ�������������������ߵ���Ч�����ߵĻ��������ʡ������ڷ�������ǿ6���ܺ˸��ʺϴ����ݡ���ģ����ȼ����ܼ��ͺ��˹���������Ϊ�������Ż������Ŵ������Ĺ���ֱ�500W������Ȼ����ͬ�ڷ�����Gaudi AI����������Ʒ�����Ƶļ�������Ʒ��ȣ��ܺ���Ӧ�еĴ��ۣ��������������������������¡�
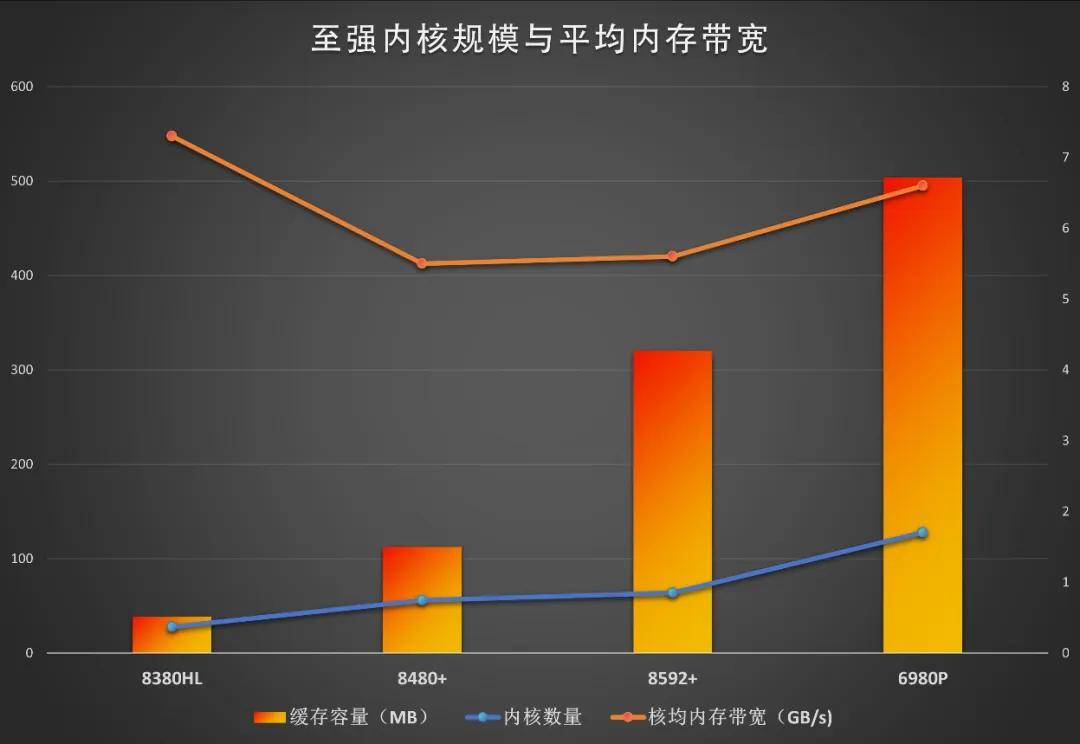
�ڴ棨DRAM�������ݴ洢�������ݣ�����ص�ʹ���������ٵ��Ѷȴ��ھ���ܡ�����ڴ沢û��մĦ�����ɵĹ⣬�������ܶȵ����������CPU��GPU�ķ�չ���ڴ�����ͺ���CPU�ں���������������һ���������⣺ƽ��ÿ���ں˵��ڴ���������������������ֵ��ˡ�Ʃ���������ǿ����չ�������ں���28���ڴ��ǰ�ͨ��DDR4 3200�������ϵ��ڴ��ܴ���Ϊ205GB/s��ƽ��ÿ��7.3GB/s���Ĵ���56��60�ˣ��ڴ��ͨ��DDR5 4800���ܴ���307GB/s��ƽ��ÿ��5.5GB/s�����������DDR5 5600���ں������ӵ�64��ƽ�������Ľ��������ġ������ǿ����չ��������Ȼ��������һ����DDR5�ڴ棬�������ں�������������������ڴ�������������Ȼ��Ǹ����ϡ�ͬʱ���������̵�CPU����������Ծ���Ĺ��̵���Ҳ����ͬ�������⡣Ϊ���ֲ��ڴ�����������������⣬���Ĵ���ǿ����չ���������������ڿ�ѧ������ͺ�������HBM�����������������ĩ���������������֧��CXL 2.0�ڴ���չ��
����ǿ6900P�ϣ��ڴ��������ڵõ��˱ȽϺõĽ�������漰�����Ƕȣ�
1.������ĩ�����档ǰ���ᵽ����6900Pÿ�������ṩ4MB L3���������ﵽ��504MB���ֱ����Ĵ���4.5���������1.6�������ң���ǿ��ȫ����ܹ�ʹ�������ں˷���ĩ��������ӳ�����������̵�һЩ��Ʒ�и��ŵı��֣����粻��Ҫ����㵥Ԫ������ӳپ��������ּܹ�Ч�ʸ��ߵ�����Ҳ����ǿ�ں�������������»��ܴ�����������Ĺؼ�ԭ��
2.DDR5�ڴ�˫������������������ǿ6900ϵ��֧��12ͨ��DDR5 6400���ܴ������Դﵽ614GB/s��ƽ��ÿ�˵Ĵ������»���5GB/s��ˮƽ��6900P��֧�������ڴ�MRDIMM��Ƶ��������8800MT/s���ܴ����ﵽ��845GB/s��ƽ��ÿ��6.6GB/s��Ҳ���Գ�����ǰ������Ʒ���������ת���ں��������ӡ�ƽ���ڴ�����������������⡣
MR��Multiplexed Rank��DIMM����DDR�ڴ������������·���DRAMͨ����1��2��Rank��ɣ�ÿ��Rank��λ��Ϊ64λ���������ECC���Ǿͻ���72��80λ������Ч��������64λ���������ڴ棨UDIMM������ֻ��1��Rank�������������ٵ�����£�������������ķ������ڴ棨RDIMM�������϶�������2��Rank�����������ڴ�ģʽ���У�һ��ֻ��ȡһ��Rank�����ݣ���һ��Rank��ʱ����ʱ������ˢ�²������Ա������ݡ�������������ȡ��ˢ��Rank���ص������˶��ꡣMRDIMM�����һ�����ݻ�������ͨ���������ڴ�Rank�ֱ����������������ٴӻ�����һ���Դ��䵽CPU���ڴ���������ɴ�ʵ���˴�����������һ��DDR5 MRDIMM��Ŀ������Ϊ8800 MT/s����ʵÿ��Rankֻ�൱��4400MT/s������DDR5 6400�Ѿ���ʼ�ռ������MR DIMM�ĵڶ���Ŀ���Ǵﵽ12800 MT/s��Ԥ����2030�����������������17600 MT/s��
3.CXL �ڴ���չ�����Ĵ���ǿ����չ��������ʼ����CXL֧�֣���ʱ��1.1�汾����ʱҲû�й���֧��Type 3�豸��Ҳ����CXL�ڴ棩���ӵ������ʼ��ʽ������CXL 2.0������Type 3����������չ�ڴ������ʹ���������ǿ6�ϣ�CXL�豸��Ӧ�ý���Ϊ�ռ����ؼ���CXL2.0���豸���Լ�������ݵ�CXL1.1�豸��Ԥ�ƶ���½��ӿ�֡�
�����ص�˵һ��CXL�ڴ�����ơ�CXL2.0֧����·�ֲ棬ʹһ�������˿ڿ��ԶԽӶ���豸�������ṩ��ǿ��CXL�ڴ�ֲ�֧�֣���ʵ�������ʹ�����չ����ǿ6֧��3��CXL�ڴ���չģʽ��CXL Numa Node��CXL Hetero Interleaved��Flat Memory��

��CXL Numa Nodeģʽ�£�ϵͳ�ı��ڴ��CXL��չ�ڴ汻��Ϊ����������Numa�ڵ���п��ơ�ÿ��Numa�ڵ㶼���Լ����ڴ��ַ�ռ䣬ϵͳ������Ӧ�ó�����Խ�������䵽��ͬ��Numa�ڵ㣬�Ӷ��Ż��ڴ��ʹ�á�CXL Numa Nodeģʽ��������Ҫ��ϸ�ڴ������Ӧ�ã�����ͨ������ϵͳ���������������Hypervisor����Ӧ�ó������������ֲ�����ڴ档
Hetero Interleaved���칹��֯��ģʽͨ����ϵͳ�ı��ڴ��CXL�ڴ�����һ���γ�һ��ͳһ��Numa�ڵ㡣ÿ���ڴ��ַ�ռ��е����ݿ��Խ���洢��DRAM��CXL�ڴ��У��Ӷ������ڴ�����������ӳ١��칹��֯ģʽ�����ڶ��ڴ�����и������Ӧ�ã��ر��ǵ���Ҫ��DRAM��CXL�ڴ���ʹ��ʱ����ģʽֻ�����䱸���ܺ˵���ǿ6700P��6900P�ϲ�֧�֡����轫ÿ����ǿ6900P��64ͨ��CXL���������Զ�������256GB/s���ڴ���������������Ϳ���ʵ��TB�����ڴ�����������൱�ɹ۵ġ�
Flat Memory��ƽ���ڴ棩ģʽ�£�CXL�ڴ�ͱ��ڴ汻��Ϊ��һ���ڴ�㣬����ϵͳ����ֱ�ӷ���ͳһ���ڴ��ַ�ռ䡣Ӳ�������ķֲ��������ȷ�������������ȴ洢�ڱ��ڴ��У���Ҫ���ݴ洢��CXL�ڴ��У��Ӷ�����ȵ������ڴ�ʹ��Ч�ʡ�ƽ���ڴ�ģʽ���ļ�ֵ����������������������CXL�ڴ���չ����������ģʽ���������е���ǿ6����������ƽ���ڴ�ģʽҪ����ڴ��CXL�ڴ���1:1���ã�����Ϊ������Ӳ���ɰ졢����������ԡ�������ԣ�ƽ���ڴ�ģʽ����ǿ6ʱ�������á���Ч��ֱ�۵�ģʽ��������ΪCXL�ڴ���չ����Ҫģʽ��
��ǿ6����ǿ�����״ν������IOоƬ��������ͨ��Chiplet��ʽ��װ��һ�������ǰѸ���װ�������������ӳ����ˡ�
���Ĵ���ǿ����չ��������Ӣ�ض�����Chiplet��Ƶ���ǿ����������XCC�汾�ڲ���4��оƬͨ��10��EMIB�Ե����ӣ�ÿ��оƬ�ṩ15���ںˡ�2ͨ���ڴ��������1����ٵ�Ԫ���Լ�UPI��PCIe PHY���ɡ����⣬������ͨ��EMIB��װ4��HBM��
�������ǿ����չ������ʹ��2��оƬ��װ���ɣ���ʹ�õ�EMIB�������Լ��٣���Ӧ��Ҳ��Լ��оƬ�������Ȼ�ں������������ӣ���Ҳ��ʧ��UPI��PCIe��������Ҳ�����ܹ�����HBM��
�������칤���ݽ���ƫ�ؼ������ܺ;�����ܶȵĴ������ںˣ���ƫ�ظ����źŻ�����IO�����������칤�յ�Ҫ������˲��죬��ˣ����͵�Chiplet��ƽ������IO���룬�ֱ�Ӧ�ò�ͬ�����칤�ա�Ӣ�ض���14������ϱ���������ַ�ʽ����ΪCompute Tile��SoC Tile��IO Tile��Graphic Tile������Ponte Vecchio��Ӣ�ض�Data Center GPU Max����Foveros��EMIB��������47��СоƬ��װ��һ�𣬰���Compute Die��Base Die��Rambo��IO Die�ȡ�
��ǿ6����Ҳ��ֳɼ��㵥Ԫ��Compute Tile����IO��Ԫ��IO Tile�����ֱ���Intel 3��Intel 7�������졣
���㵥Ԫ
�����ռ�������Ϣ��������Ч�ˣ�Ŀǰֻ������һ�ּ��㵥Ԫ����ƣ�ÿ����Ԫ����ṩ144���ںˡ�4���ڴ����������ͨ�����������ܺˣ����������ּ��㵥Ԫ����ƣ��ɷֱ�������ϸߺ������еȺ������ͺ����Ĺ��
��ǿ6900Pʹ�����������㵥Ԫ��ÿ����Ԫ43���ںˡ������ڴ���������ܹ�����129���ںˣ�ֻʹ��128������12���ڴ�ͨ�������ּ��㵥Ԫ���ҳ�֮Ϊ��ԪA��������ԪA���ɵĴ���������ΪUCC��

δ��������6700P������Ȼ�ܴ����е�·�ͺŹ滮Ϊ16~80�ˣ���·�ͺ�Ϊ8~86�ˡ���ԪA��4���ڴ�ͨ����������ԪA��Ͽ����ṩ���86�ˣ�����Ӧ�ò�����48�ˣ��������ε��ں�������ʵ��̫�࣬Ҳ̫�˷�EMIB�ɱ��������ֹ�ģ�Ĵ���������ΪXCC��48�����µ��еȺ�������ΪHCC��ʹ��һ��ר�ſ����ĵ�ԪB��ÿ����Ԫ�ṩ48���ں˺�4���ڴ��������HCC����������Ԥ����24�����ҡ�8��16�˵�6700P����ΪLCC����Ҫʹ�õ����ֵ�ԪC��16���ں˺�4���ڴ��������

ͨ��ʹ��3�ּ��㵥Ԫ������ϣ���ǿ6���ܺ˿��Թ�����ȴ�8~128�˵ġ��dz����ܵĹ��Ҳ����������Ϊ�������������ֻ��һ�ֹ����㵥Ԫʵ����չ����ƣ�Ӣ�ض���Ҫ������Ų�ͬ��оƬ�ijɱ�����ߡ�������Ϊ������Ӣ�ض����ȿ������ܵĽ�������ȣ���ǿ6���ڴ�����������ڼ��㵥Ԫ�У����ں˸������ӳٸ��ͣ���ʹ��������˵�Ԫ���ʹ�õ������Ҳ��ֵ�õġ���Σ���ǿ6���ܺ˸���ͬ��ģ���ں������滮��ͬ�������ģ�������ڽ��ͺ˼���ӳ٣��������п���LCC����Խϵ͵ĺ������û������ߡ����ϣ�Ԥ����ǿ6���ܺ����ͬ�ȹ�ģ���������̵IJ�Ʒ���ɿ��ܻ�ӵ���ڴ��ӳٵ͡������ӳٵ͵����ơ�
IO��Ԫ
IO��Ԫ���棬��ǿ6900��6700ϵ�ж�ʹ��2����ͬ��IOоƬ��ÿ��IOоƬ��2��IOģ�顢4��UIOģ�顢2��������ģ�飬�Լ�IO����ӿڹ��ɡ�ÿ��IOģ���ṩx16 PCIe��CXL���ӣ�ÿ��UIOģ���ṩx24 UPI2.0������Ϊx16��PCIe��CXL��ÿ��������ģ���ṩDSA��IAA��QAT��DLB��������һ����
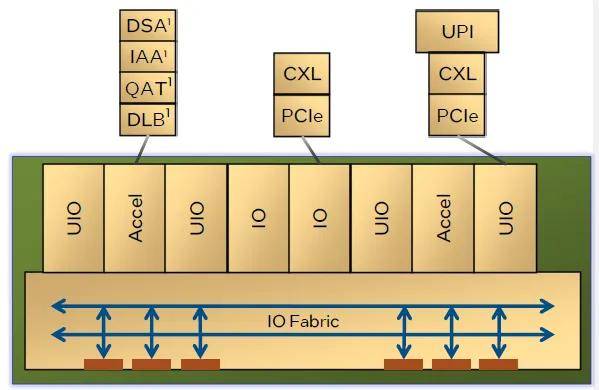
����η�������ǿ6900PΪ��������IO��Ԫ�ܹ��ṩ8��UIO��4��IOģ�顣����6��UIO�����ṩ6��UPI2.0������ʣ���2��UIO��4��IOģ�������ṩ6��16=96ͨ����PCIe 5.0��˫·��ǿ6900P��UPI�������ʸߣ�24GT/s�����������20GT/s���Ĵ���16GT/s������������Ҳ������50%��
���ڻ�δ������Ҳ��������Ʒ����ǿ6700ϵ�У���������Ҫʹ�ù�ģ��С�IJ�����ֻ�ṩ���4��UPI���ڶ�·�Ļ�����PCIeͨ��Ҳ��������������ʹ��ˣ���ǿ6700ϵ�еĵ�·�ͺ��ڽ�����UIO����ΪPCIe֮����۾Ϳ����ṩ���136��PCIeͨ������64ͨ��CXL������õ�·��ǿ6700��ϰ�����幹��˫�ڵ����������һ�������ڵ�PCIe/CXL��չ������272 /128��ԶԶ������֪���κ�˫·�����������ֻ�����ܻ��Ϊ�µijػ���̬�����Ը��ߵ��ܶ��ṩNVMe�洢��CXL�ڴ桢�������ȡ�
�� ��
����Ӣ�ض���14nm��10nm���칤�յĵ�������������һЩ���⣬���´�ǰ������ǿƽ̨�ڡ���ս������ƴ�����������Ա������������������ǿ6��������ȫ��ת���������EUV���칤�տ���û��������ǿ6��ʵ�������������������������ڴ�����ȹؼ�ָ��ȫ�������������У�һ�仰�ܽ���������ʹ����ı���ȫ����������ǿ6900Pϵ���ڸ�����Ŀ�IJ��Ե��У���������������Ͷ����Ա����ƣ����ǰٷ�֮ʮ������ʮ�Ľ�������������Ҳʹ��Ӣ�ض�����ȫ�澺����ѧ���㡢�����ݡ�AI�����������������
���⣬��ǿ6����ʵ�ּ�����IO�Ľ��Ҳ����ǿ6��δ���IJ�Ʒ����������ȷ�����ĵ�·�����Գ�ַ���Chiplet�����ơ���Chiplet�������ͳɱ���������ʵ��ֶ��������ġ�Chiplet�ļ�ֵ���������á��ع���Ӣ�ض�����������ע��ϸ���г��ĸ��ţ���Ʒ�߷dz����ӣ���ȷ����Chiplet���Դﵽ�°빦����Ч�������Ƿdz��ڴ���ǿ6������Ʒ��½�������ܹ���ҵ�����ʲô������������

��վ���� | ��濯�� | ��ϵ���� | ��Ȩ���� | ������ | ��Ѷ�� | �������� | Ů���� | ��վ����
�����й���Ȩ���� δ������ �����ƻ��� Copyright © 2012-2017 http://www.48868.com.cn/, All rights reserved.
վ����Ϣ������748492175@qq.com ���dz����ţ� | QQ��748492175









